
Historical record of incidents for yasoon
Report: "Automation actions rules were failing for a few customers due to an infrastructure change"
Last updateWe are made aware of some of our Microsoft 365 Automation actions failing in Jira Cloud instances. We have identified the issue and rolled back the responsible code & infrastructure change. The change was implemented in preparation to fully support Atlassian Cloud data residency. We are currently monitoring the issue and apologize for the interruption.
Report: "Partial Graph API outage"
Last updateThe issue has been identified and a fix is being implemented.
Creating and loading of chats might not work reliably, additional Microsoft entities may be affected aswell.See official status on Microsoft here:https://admin.microsoft.com/Adminportal/Home?#/servicehealth/:/alerts/TM1087772
Report: "Partial Graph API outage"
Last updateThe issue has been identified and a fix is being implemented.
Creating and loading of chats might not work reliably, additional Microsoft entities may be affected aswell. See official status on Microsoft here: https://admin.microsoft.com/Adminportal/Home?#/servicehealth/:/alerts/TM1087772
Report: "Creating Outlook meetings is not working"
Last updateThis incident has been resolved.
The problem was identified and we performed a rollback.
Creating Outlook meetings in all yasoon Products is currently not working. We are currently investigating the issue.
Report: "App is not installable from the Atlassian Marketplace"
Last updateThis incident has been resolved.
A fix has been implemented and we are monitoring our error logs. The problem originated from a changed service on Atlassian Cloud side, where a security certificate was returned with a different mime-type since early morning on the 31th of January, causing our security validation to fail.
We have identified the issue and a fix will be rolling out shortly.
We are currently investigating an issue that our apps cannot be installed from the Atlassian Marketplace.
Report: "Jira calendars not working in Confluence Calendars"
Last updateWe experienced an issue where Jira calendars with sharing permissions were not functioning correctly in the Confluence Calendars app (cloud only) for approximately 13 hours. This incident was due to a faulty dependency in our cloud infrastructure, which prevented the calendars from being loaded correctly. We investigated the root cause and implemented a bug fix.
Report: "Built in automations & todo sync not executed for ~3hours"
Last updateFor about three hours, we had in issue with our webhook processing which did not execute our handlers correctly. In addition to that, our automatic retry process also did not work as expected, so a few Todo sync updates and built-in preset automations were not processed correctly. We are investigating the root cause of this failure in more depth.
Report: "Automation rules (via Jira Automation & built-in via presets) delayed and / or missing"
Last updateWe experienced an issue on Friday, the 29th of November, where some of our automated rules were not executing or delayed by a few hours. Due to a code change on our side our production queueing infrastructure experienced a major congestion, where we needed to clear out a few failed executions that were being retried over and over again, blocking all other events from being processed. We will be looking into improving the robustness of this particular queue.
Report: "App availability impaced"
Last updateThis incident has been resolved, we have not seen any recurrence of the problem. We'll implement additional measures to prevent this scenario from happening again.
A infrastructure fix has been implemented and we are monitoring the results. We will share a postmortem soon.
We are currently experiencing a major outage due to overflowing caches. We are trying to restore availability as soon as possible.
Report: "Automation triggers fail"
Last updateThe issue has been resolved, sorry for the inconvenience. We'll implement better monitoring going forward to prevent this concrete error from happening again.
Triggers in our application used for Jira automation fail with the error "Queue not initialized". Root cause has been identified and a fix is currently being deployed
Report: "Project calendar not working in team managed projects"
Last updateThis incident has been resolved.
It currently is not possible to use the Outlook calendar in Jira team managed projects. We are looking into it - sorry about the inconvenience!
Report: "Some Teams (Smart Connect for Jira) bot functions were not working correctly"
Last updateDue to an expired secret, some functions of the Teams bot were not working correctly. We are working on a custom alerting solution that will notify us in advance in the future, as Microsoft does not send out any notifications proactively.
Report: "Sending bot messages via Automation not working"
Last updateWe have confirmed this issue has been fully resolved now. Sorry for any inconvenience this may have caused!
A fix is in the process of rolling out and should be live for all instances in ~1hour
We have identified the issue is related to a missing permission on a database index. We are working on a solution right now.
It's currently not possible to use the "send bot message" Automation action - we are investigating the issue.
Report: "API Services not available for DataCenter Products"
Last updateDue to an invalid deployment, the Cloud services for our Data Center products were not reachable. Timeline: 9:00 am, start of the invalid deployment 9:25 am, error mentoring caught the error and informed the incident team 9:40 am, operations team intiated an rollback to the previous version 9:50 am, got confirmations about the resolution of the incident
Report: "Outlook Calendars for Confluence app inactive and cannot be activated"
Last update## 🔮 Executive summary On the 5th of November 2023, we were made aware of an incident with our Outlook Calendar for Confluence app. A customer notified us on Sunday, the 5th of November, that the calendar app could not be enabled in Confluence. We were able to reproduce this issue in our own environment. We immediately started investigating the issue and found due to a path change in the location of the translation files, which was originally done for our Jira apps, the app would not enable anymore in Confluence. We released a fixed update on the 6th, hoping to re-enable the app for all customers. Unfortunately, once the corrupted update was rolled out to all customer instances, the app would not re-enable on it’s own, even after the fixed update was deployed. On Tuesday, 7th, we send out an email communication to all affected customers, explaining the need to perform a manual update of the app. In parallel, we worked with Atlassian Marketplace support to enable the app for all customers automatically. After a week, on the 16th of November, we were able to resolve the issue fully for all customers. ## ⛑ Postmortem report | **Instructions** | **Report** | | --- | --- | | ⚠️ Leadup | We switched our apps build process to use translation files from a different path. Unfortunately, while making & validating the change to our Jira apps, an cross-dependency to our Confluence app was not discovered, allowing the new translation paths to go live for the Confluence app as well. | | 🙅♀️ Fault | Once the Atlassian Marketplace picked up the app update & started rolling it out to all customer instances automatically, the app became disabled for all customers. Manually enabling the app again fixed the issue after we rolled out a second update on Monday. Unfortunately, the second update failed to re-enable the app for all affected customers, so a manual action was necessary \(at first\). | | 🥏 Impact | The app was disabled for all customers, removing all UIs entry points from Confluence and preventing users from accessing the app. | | 👁 Detection | We learned about the issue a few hours after the update rolled out on the Marketplace on Nov. 5th. | | 🙋♂️ Response . | After the noticed the issue, we immediately began troubleshooting and located the issue in the translation paths section of the Atlassian Connect manifest file of our app. Apps pointing to non-existing translations will validate the schema correctly and also install, but fail to get into the “Enabled” state. Once in “Disabled” state, there is no way for a Marketplace vendor to get the app back to enabled. | | 🙆♀️ Recovery | Once we sent out responses to the support tickets and an email communication to all affected customers, we saw apps being manually re-enabled. After ~a week, Atlassian confirmed the run of a script which re-enabled the app for all affected customers, with the exception of a few instances which churned during that period of time. | | 🔎 Root cause identification | The root case was already identified during the development of the fix. A change to a build process for our Jira apps caused a missing translation file path to be introduced for our Confluence app. | | 🤔 Lessons learned | We will use this incident as a learning to improve in the following areas: Improve our release process to validate a full install of the resulting Connect app manifest file to prevent any erroneous updates to be delivered to customer instances. This is especially important since the Atlassian Marketplace does not seem to validate all edge-cases before installing the app in the cloud instances. | ## ⏱ Incident timeline | **Time** | **What** | | --- | --- | | `2023-11-05 9:48 PM CET` | First email received from customer notifying us about the issue | | `2023-11-06 10:22 PM CET` | Raised ticket with Atlassian, letting them know we cannot fix the issue on our own, due to a quirk in how the Marketplace installs updates in cloud instances | | `2023-11-06 22:42 PM CET` | PR merged with the fix and update released on the Atlassian Marketplace | | `2023-11-07 15:00 PM CET` | Send out email communication to all affected customers, letting them know about the issue | | `2023-11-16 15:30 PM CET` | Atlassian notifies us that a script has been executed manually to enable the app again for all customers | ## ✅ Follow-up tasks List the issues created to prevent this class of incident in the future. | **Problem** | **Action items** | | --- | --- | | Reliance on CI/CD alone to catch issues was not sufficient to catch all issues with Connect manifest. Schema validation & Atlassian Marketplace do not catch all error cases, allowing erroneous app updates to ship to all customer instances | Introduce new pipeline checks, validating Connect manifest install in production environment before go-live |
We have successfully worked with Atlassian to re-enable Outlook Calendars for Confluence on all instances, so no manual activation should be necessary anymore. Sorry for the disruption, we'll make sure to post a post mortem in a timely manner.
We are still working with Atlassian to bulk-enable the app for all instances again. It's still possible to manually enable the app again, so we are lowering the impact.
After monitoring the situation, it appears that the app will not re-enable itself automatically, but this can be done manually via "Manage apps". We are working with Atlassian to re-enable the app for all customers.
A fix has been implemented. Currently a manual update of the app is required via "Manage apps", but should be picked up automatically after 24h.
A fix has been implemented. Currently a manual update of the app is required via "Manage apps", but should be picked up automatically after 24h.
We have identified a deployment issue with our Outlook calendar app. The app can currently not be used, as it cannot be activated since the last update. We are working to provide an update today that will fix the issue.
Report: "JSM chat notifications not posted"
Last updateAfter misconfiguring the production Azure Bot behind the JSM Teams portal app, some chat notifications could not be delivered. The misconfiguration could be identified within minutes and the issue could be resolved after ~20 minutes.
Some JSM chat notifications could not be delivered due to a misconfigured Azure Bot.
Report: "Todo & Smart Connect for Jira not reacting to Jira changes"
Last updateThis incident has been resolved.
We are continuing to monitor for any further issues.
A fix has been implemented and we are monitoring the results.
The issue has been identified and a fix is being implemented.
Report: "Webhooks reliability issues"
Last updateWebhook handling was degraded by some workers with incorrect initialization. Affected dates 2023/08/23 2pm-4pm UTC 2023/08/24 8am-11am UTC Impact: Roughly 20% of handled webhooks have been affected by the incident. That lead to missing Todos synced or missing channel notifications in Teams. Fix: Initialization script has been updated and made more robust. We are monitoring the situation
Report: "Microsoft Graph services outtage"
Last updateThis incident has been resolved.
Microsoft is currently experiencing an outage across multiple services, which also impacts our integrations. You might not be able to create Microsoft Teams chats or channel conversations and other areas might be impacted as well. https://admin.microsoft.com/Adminportal/Home#/servicehealth/:/alerts/MO571683
Report: "Teams and potentially other functions interrupted"
Last updateThis incident has been resolved.
Since our morning deployment around 8AM CEST, we have been observing increased errors when working with the Teams functionality of our app. We have not yet identified the root cause, but have rolled back the change and everything should be working again.
Report: "Calendar not accessible in Microsoft 365 for Jira"
Last updateA fix for this incident has been released on Friday and should be available for everyone as of now - sorry for the inconveniences.
We have identified an issue with our calendar view in our Microsoft 365 for Jira app. An fix is currently being deployed and should be available in the next 24 hours.
Report: "Viewing shared chats & creating calendar events in shared calendars is currently impacted"
Last updateWe have released a fix for this issue.
We have located the cause of the issue and are in the process of rolling out a fix
Report: "Server outtage"
Last update## 🔮 Executive summary On the 27th of November 2022, we were made aware of an incident in our backend infrastructure. An Atlassian Cloud Fortified check notified us, that new customers were not able to install our app correctly. We were able to reproduce this issue in our own environment. We immediately started investigating the issue and found that our main Redis instance, which handles asynchronous job processing and caching, had run out of available memory, and therefore all calls to Redis were failing. Once the issue was located, we started a task to temporarily increase the Redis memory \(from 3GB to 60GB\), to stabilize the backend and investigate the root cause in more detail. After around 30 minutes the increase, our services were back online. ## ⛑ Postmortem report ### ⚠️ Leadup We switched one of our apps \(To Do for Jira\) to our new backend infrastructure, as it was still relying on an older version of our API. In this process, we also switched the event processing \(Jira webhooks\) over to our new backend. During the review of the code, we failed to notice a missing flag in our Redis queueing code, which removed completed jobs from Redis. ### 🙅♀️ Fault Once the mentioned code was deployed to our application servers, it slowly increased the used memory of the Redis instance over a period of three weeks. Once at 100% memory usage, the Redis instance started returning errors, which only worsened the issue further and escalated even through the overprovisioning AWS has in place. ### 🥏 Impact This issue impacted all our customers using the Teams app, which was completely unusable during the incident, as it was relying on the availability of the Redis instance. In addition, other services, as webhook processing and starting new trials / installing our app, was impacted. ### 👁 Detection We only learned about the issue from the Atlassian Cloud fortified monitoring service, which alerted us to the installation of new apps issue. ### 🙋♂️ Response On Sunday morning, after the second alert from Atlassian was received, we started investigating the issue. One team member quickly attributed the issue to the out-of-memory issue in Redis. Our logs clearly indicated the error, so thankfully, we were able to locate it in under 30 minutes and start the recovery process. ### 🙆♀️ Recovery Once the issue was located, we started a task to temporarily increase the Redis memory \(from 3GB to 60GB\) to get the backend service back up. After ~20 minutes AWS was able to provision the resized instance, which restored our API availability. ### 🔎 Root cause identification Once the recovery was confirmed, we started looking into the root cause of the issue. We identified the issue to be related to a rework we did a few weeks earlier, which ported our To Do app functionality to our new backend stack. During the process, we failed to notice that a crucial flag was missing, that prevented the cleanup of processed jobs from Redis. Over the course of three weeks the Redis cluster slowly increased in memory usage, until it reached 100% usage and started failing with out of memory errors. A few places in our backend services did not handle the failure correctly, and stopped working completely \(Webhook processing, installation / uninstallation of apps, the complete render-function for our Teams app\). ### 🤔 Lessons learned We will use this incident as a learning to improve in the following areas. a\) Improve defaults for new services relying on the Redis instance, namely removing completed jobs from Redis by default. b\) Introduce new monitoring for the memory usage of the Redis cluster to be notified of increasing memory in time. c\) Introduce a shared piece of code that will offer a failure resistant way of accessing Redis as a cache, to avoid failing services because of a missing cache. d\) Measure daily throughput of Redis and introduce a appropriately sized instance to have at least 48h leeway from being notified about a memory issue until it impacts production services. ## ⏱ Incident timeline | **Time** | **What** | | --- | --- | | `2022-11-26 17:01 UTC` | First email received from Atlassian monitoring that our target SLA of 99% successful new installations went down to 90% | | `2022-11-27 00:02 UTC` | Second email received from Atlassian monitoring that our target SLA of 99% successful new installations went below 10% | | `2022-11-27 07:18 UTC` | On-call engineer noticed the issue and started investigating the failing trials and the non-functioning Teams app | | `2022-11-27 07:38 UTC` | The issue was detected to be an out-of-memory issue in the main Redis instance which is used for caching and asynchronous jobs. A manual resize of the Redis cluster was triggered to restore functionality quickly | | `2022-11-27 07:58 UTC` | Redis cluster was resized and accepting connections again, which immediately full functionality across our service again | ## ✅ Follow-up tasks List the issues created to prevent this class of incident in the future. | **Problem** | **Action items** | | --- | --- | | Monitoring of Redis cluster was insufficient | Introduce new monitoring to alert the responsible colleagues ahead of time, once the Redis memory usage passes a certain threshold \(planned: 20%, 50%, 90%\) | | Some of our services are too reliant on the uptime of the Redis cache instance, even though it’s not critical for the service | Introduce circuit-breakers to avoid reliance on Redis cache availability, in cases where we can recover without Redis being available | | | Define SLAs on how much leeway/buffer memory the Redis instance should have in case of a processing failure. E.g. in case we regularly expect around 1GB/day of throughput in Redis, size the instance accordingly so we have at least 48-72 hours to react to processing issues |
We are still investigating the root cause of the Redis issue but the service has been fully restored for now.
We have identified an out of memory error in our main Redis instance, resulting in a cascading error. We have temporarily increased the memory to restore the service and will be starting to look into the root cause.
Our apps are currently unavailable due to an outtage - we are looking into it and will provide an update asap.
Report: "Teams for Jira not accessible"
Last update## 📋Incident overview | **Postmortem owner** | Tobias Viehweger | | --- | --- | | **Incident** | [https://status.yasoon.com/incidents/tys9v7ng4wm0](https://status.yasoon.com/incidents/tys9v7ng4wm0) | | **Priority** | P1 | | **Affected services** | Microsoft Teams for Jira - Smart Connect & Microsoft 365 for Jira \(creating and viewing chats & conversations in Jira\) | | **Incident date** | 2022/10/24 14:01 UTC | | **Incident duration** | 55 minutes \(resolved at 14:56 UTC\) | | **Incident response teams** | Development support | | **Incident responders** | Tobias Viehweger | ## 🔮 Executive summary On the 24th of October 2022, we were made aware of an incident in our Microsoft Teams for Jira app \(also included as part of our Microsoft 365 for Jira app\). We were able to reproduce this issue in our Jira production instance. We immediately started investigating the issue and found a faulty backend commit that introduced an unwanted change in production. We immediately started rolling back to the last known version, which took about 30 minutes until all affected app servers were back on the working version. 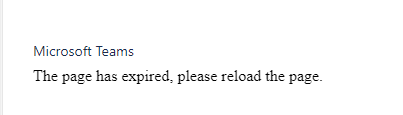 ## ⛑ Postmortem report | **Instructions** | **Report** | | --- | --- | | ⚠️ Leadup | When troubleshooting an authentication issue that appeared in our logs files since a few weeks, we introduced a new piece of log that would give us more information about the error. With this change a seemingly minor refactoring of a central piece of authentication code took place, which turned out to be faulty. | | 🙅♀️ Fault | Once the mentioned code was deployed to our fleet of application servers, Jira users trying to use our Teams functionality were presented with an error. Due to the change, our app servers classified all requests coming from the Teams app as unauthorized, resulting in an error shown for all Jira users, stating **“The page has expired, please reload the page.”** | | 🥏 Impact | This issue impacted all our customers using the Teams app, which was completely unusable for about an hour. After ~15 minutes, the first support request was raised, followed by three other support requests in the following minutes. | | 👁 Detection | We only learned about the issue from the first incoming support request, since neither our static type checker nor our automated pre-deployment tests caught the issue. | | 🙋♂️ Response . | Once the first support ticket came in, we immediately started investigating the issue. One team member immediately attributed the issue to a just-released change. We notified the first customer immediately about this and once the recovery started, contacted all other customers with open support requests. | | 🙆♀️ Recovery | We immediately started the roll back to the last known good version of our backend software. After a few minutes, the first restored app server resulted in partially restored functionality, sometimes after a page reload. Over the course of the next 30 minutes all app servers were rolled back to the fixed version. | | 🔎 Root cause identification | A combination of human-error and software issues resulted in this faulty change to be deployed to production. The error did not come up in the dev environment. The code review for this change did not catch the error. The static type checker did not catch the error. The automated pre-deployment tests did not cover this specific area of code, letting the deployment continue | | 🤔 Lessons learned | We will use this incident as a learning to improve in the following areas: Improve and validate the static type checker error detection. Make sure code reviews for central points of failure \(e.g. authorization related\) are thoroughly tested in the staging environment and reviewed with utmost care. Better monitoring to catch this kind of production error before the first support request is even raised | ## ⏱ Incident timeline | **Time** | **What** | | --- | --- | | `2022-10-24 13:49 UTC` | First app server is updated to the faulty version, no widespread outage yet | | `2022-10-24 14:01 UTC` | All app servers are updated to the faulty version, resulting in all customers having issues access the app | | `2022-10-24 14:17 UTC` | First support ticket documenting the incident is raised | | `2022-10-24 14:31 UTC` | Rollback to last known good version started | | `2022-10-24 14:33 UTC` | First app server is updated to the previous version, recovery for customers started | | `2022-10-24 14:56 UTC` | Last app server is updated to the previous version, recovery for all customers is completed | ## ✅ Follow-up tasks List the issues created to prevent this class of incident in the future. | **Problem** | **Action items** | | --- | --- | | Static type checker did not catch the issue | Validate and improve type checker correctness to avoid this type of issue in the future | | Missing automated test for cental piece of code | Implement tests for this part of the apps authentication logic to prevent regressions | | Rollback to working version could be faster | Investigate if we can improve rollback time to quickly rollback to an earlier version |
Using the Teams features in Jira currently only shows “The page has expired, please reload the page.”
Report: "App not active in Jira Cloud for some customers"
Last updateThis incident has been resolved.
We are continuing to monitor for any further issues.
We have implemented a fix and it should be working again for all customers.
We are still working on a fix - as a manual workaround you can go to the admin settings and activate the app features manually
We are currently working on a fix that all the apps are not active in Jira Cloud (except Teams).
Report: "Creating and updating Confluence calendars is currently not possible"
Last updateThis incident has been resolved.
We are currently investigating this issue.
Report: "Login issues due to Microsoft outage"
Last updateThis incident has been resolved.
AzureAD is currently having a major outage, and it's not possible to login / work with our apps. Please follow @AzureStatus on Twitter or check your Microsoft 365 dashboard for updates.
Report: "Authentication issues with Jira Cloud"
Last updateThe issue has mostly been resolved, please follow the Atlassian Statuspage for more info.
The issue is related to an Atlassian outage, please follow their status page as well: https://jira-software.status.atlassian.com/
We are currently investigating an issue where users are not able to login from Outlook.
Report: "Partial Microsoft Exchange outage"
Last updateThis incident has been resolved.
Affecting Outlook Meetings for Jira and others --- Users can't access Exchange Online EX223208, EX223231, EX223235