
Historical record of incidents for Uploadcare
Report: "Issue with Uploading from Social Sources (Dropbox, Facebook, etc.)"
Last updateWe’re currently experiencing issues with uploading files from social sources such as Dropbox, Facebook, and others via the Uploadcare uploader. Users may be unable to select or upload files from these sources. The root cause is under investigation, and our team is working to resolve the issue as quickly as possible. Uploads from local and direct sources are unaffected. We’ll provide updates as we learn more.
Report: "Unavailability of uploading from 3rd Party Services"
Last update## Incident Summary On November 25, 2024, from 16:01 to 19:44 UTC, the “Uploading from 3rd Party Services” feature of our platform was unavailable. This feature allows users to upload files from social networks and storage services like Dropbox, Facebook, Google Drive, and Instagram. ## Timeline * **15:50 UTC** – A server configuration update was initiated to streamline deployments in our Kubernetes environment. * **16:01 UTC** – The outage began as requests to the “Uploading from 3rd Party Services” feature failed to be processed. * **19:00 UTC** – Investigation revealed that the application networking was incorrectly configured. * **19:15 UTC** – A fix was implemented to re-configure the application networking. * **19:44 UTC** – The incident was fully resolved, and service was restored. ## Root Cause The outage was caused by a synchronization issue between repositories during a server configuration update. This misalignment between repositories, compounded by a lack of explicit configuration, led to the service outage. ## Impact For approximately 3 hours and 43 minutes, users were unable to upload files from third-party services. ## Challenges During Resolution This type of issue is difficult to catch in a staging environment because the traffic profile does not reflect production-level demand. Although the alert system worked as intended, delays in responding to the alert contributed to the resolution time. ## Resolution The application configuration was updated and service functionality was fully restored at 19:44 UTC. ## Action Items ### Short-term * Improve feature status monitoring and alerting to detect outages faster. ## Long-term * Improve synchronization processes between repositories to avoid dependency misalignments. We sincerely apologize for the disruption this caused to our users. We take this incident seriously and are committed to implementing the above action items to prevent similar occurrences in the future. Thank you for your patience and continued trust in our platform. If you have any questions or need further details, please don’t hesitate to reach out.
Issue has been resolved
Report: "Elevated URL API Errors"
Last update## Incident Summary On 26 November 2024, an issue with our URL API was identified, causing a partial outage of the service from 14:31 to 15:00 UTC. ## Timeline * **14:20 UTC** – A CDN configuration change was made to improve the Auto Format feature in the URL API. * **14:31 UTC** – Service degradation began as increased traffic overwhelmed our origin servers due to cache key changes. * **14:37 UTC** – Alert notifications were received by our team. * **14:58 UTC** – The CDN configuration was rolled back. * **15:00 UTC** – The incident was fully resolved, and service was restored. ## Root Cause The issue was caused by a CDN configuration change that altered cache key behavior, significantly increasing traffic to our origin servers. This overwhelmed our autoscaling groups, which hit their scaling limits, resulting in a service outage. ## Impact URL API degradation lasted for approximately 29 minutes. ## Challenges During Resolution This type of issue is difficult to catch in a staging environment because the traffic profile does not reflect production-level demand. Although the alert system worked as intended, delays in responding to the alert contributed to the resolution time. ## Resolution The configuration change was identified as the root cause and rolled back. The service stabilized immediately after the rollback, and full functionality was restored by 15:00 UTC. ## Action Items ### Short-term * Review and improve escalation processes for alert notifications to reduce resolution time. * Adjust staging environment testing to better simulate production traffic patterns for similar changes. ## Long-term * Assess autoscaling limits to ensure sufficient capacity for handling unexpected traffic spikes. We sincerely apologize for the disruption and are committed to learning from this incident to improve the reliability of our services. Thank you for your understanding and continued support.
This incident has been resolved.
Systems are back to normal
We're experiencing an elevated level of URL API errors and are currently looking into the issue.
Report: "Webhook Service Degradation"
Last update## Incident Summary On 25 September 2024, an issue with webhook delivery was identified, affecting clients between 10:07 and 12:19 UTC. The delay impacted webhook notifications, with no data loss but a significant delay in processing and delivery. ## Timeline * 10:07 UTC – A system configuration change was made, which inadvertently disrupted webhook processing. * 10:07 UTC – Webhook delivery issues began. * 12:05 UTC – The problem was identified and resolved, with backlogged webhooks being processed. * 12:12 UTC – The first webhook was successfully delivered after the fix. * 12:19 UTC – All queued events were processed, with delivery confirmed for all affected users. ## Root Cause The issue was caused by a configuration change that resulted in the webhook delivery system not processing events correctly. Despite initial signs of system health, the disruption went undetected due to gaps in the system’s monitoring tools. ## Impact * Webhook delivery was delayed for approximately 2 hours. * Customers experienced delays in receiving event notifications. * No data was lost, but delivery delays were significant due to a backlog in event processing. ## Challenges During Resolution * Monitoring systems indicated that components of the webhook system were healthy, which delayed identification of the underlying problem. ## Resolution * Webhook processing was restarted, and we verified that all queued events were delivered without any data loss. * The incident was fully resolved by 12:19 UTC, with all webhooks processed and delivered. ## Action Items ### Short-term * Improve the system’s monitoring and alerting to better detect issues with webhook processing. ## Long-term * Explore options to improve the resilience of our webhook delivery system, including scaling the infrastructure to better handle failures.
This incident has been resolved. We apologize for any inconvenience this may have caused.
We're experiencing a slowdown in our Webhooks service.
Report: "REST API and Upload API outage"
Last update## REST and Upload API service degradation \(incident #wvjpwt1qtpkn\) **Date**: 2024-07-08 **Authors**: Arsenii Baranov **Status**: Complete **Summary**: From 09:01:53 to 09:33:12 UTC we've experienced higher latencies and in the end a complete outage of Upload and REST API. **Root Causes**: PostgreSQL performance degradation due to human-factor. **Trigger**: Misconfiguration. **Resolution**: Changed our DBA-related processes, fixed monitoring related issue. **Detection**: Our Customer Success team detected the issue and escalated to the Engineering team. **Action Items**: | Action Item | Type | Status | | --- | --- | --- | | Fix monitoring misconfiguration | mitigate | **DONE** | | Improve DBA maintenance approach | prevent | **DONE** | ## Lessons Learned **What went well** * Due to distributed nature of Uploadcare, this incident has no effect on most of our services. This degradation didn’t affect storage, processing and serving files that were already stored by Uploadcare CDN. * Our incident mitigation strategy was right and worked immediately. **What went wrong** * This incident was detected in non-automatic way due to alert misconfiguration. * We failed to process API request during the incident. ## Timeline 2024-07-08 _\(all times UTC\)_ * 08:00 Database maintenance started * 09:01 **SERVICE DEGRADATION BEGINS** * 09:23 Our customer success team escalates issue to Infrastructure team * 09:29 Issue localised and fixed * 09:33 **SERVICE DEGRADATION ENDS**
2024-07-08 09:01:53 UTC REST API and Upload API became unavailable due to system misconfiguration. 2024-07-08 09:33:12 UTC We've identified the source of problems, deployed fixes. Service recovered. We are monitoring the situation.
Report: "Service degradation"
Last update## Upload API and Video processing services degradation \(incident #5r4zj8shr69c\) **Date**: 2023-10-02 **Authors**: Alyosha Gusev, Denis Bondar **Status**: Complete **Summary**: From 14:15 to 16:45 UTC we’ve experienced higher latencies of Upload API and with video processing due to very high interest in these services. **Root Causes**: Cascading failure due to combination of exceptionally high amount of requests to Upload API. **Trigger**: Latent bug triggered by sudden traffic spike. **Resolution**: Changed our throttling politics, increased resources for processing. **Detection**: Our Customer Success team detected the issue and escalated to the Engineering team. **Action Items**: | Action Item | Type | Status | | --- | --- | --- | | Test corresponding alerts for correctness | mitigate | **DONE** | | Improve our upload processing system to remove bottleneck that we found | prevent | **DONE** | | Fix service access issue for team members that form potential response teams | mitigate | **DONE** | ## Lessons Learned **What went well** * Due to distributed nature of Uploadcare, this incident has no effect on most of our services. This degradation didn’t affect storage, processing and serving files that were already stored by Uploadcare CDN. * Our incident mitigation strategy was right and worked immediately. **What went wrong** * This incident was detected in non-automatic way due to alert misconfiguration. * Due to hardening security standards in our organisation, not all of incident responders had access to Statuspage to update our customers in timely manner. ## Timeline 2023-10-02 _\(all times UTC\)_ * 14:15 Our upload processing queue start filling * 14:20 **SERVICE DEGRADATION BEGINS** * 15:23 Our customer success team escalates issue to Infrastructure team * 15:31 Issue localised * 15:41 Incident response team is formed * 15:51:13 Adjusted our throttling policies * 15:51:38 Increased number of processing instances * 16:40 **SERVICE DEGRADATION ENDS** Processing queues clear
From 14:15 to 16:45 UTC we’ve experienced higher latencies of from_url uploads and with video processing. We’ve identified the source of the problem, eliminated it and are monitoring the situation. These services are fully functional now.
Report: "Minor URL API degradation"
Last update# -/json/ and -/main\_colors/ operations returning 400 status **Date**: 2023-11-21 **Authors**: Alyosha Gusev **Status**: Complete, action items in progress **Summary**: From 2023-11-21 17:40 to 2023-11-22 18:40 -/json/ and -/main\_colors/ operations started to return 400 status **Root Causes**: HTTP rewrites misconfiguration **Trigger**: Deploy of the new functionality that enables our customers to save more money on traffic, and end users to experience lower load times \(improvements to automatic image optimisation\) **Resolution**: Bugfix deploy **Detection**: Our automatic tests detected the issue **Action Items**: | Action Item | Type | Status | | --- | --- | --- | | Fix rewrites | mitigate | **DONE** | | Improve visibility of failing tests notification | prevent | **DONE** | ## Lessons Learned **What went well** * Problem was detected by automatic tests * Bugfix was deployed immediately **What went wrong** * We didn’t found out that tests were failing immediately ## Timeline All times UTC * 2023-11-21 17:40: **SERVICE DEGRADATION BEGINS**. Deploy of the new functionality * 2023-11-22 16:18: Team notices failing tests * 2023-11-22 16:19: Issue localised, Incident response team is formed * 2023-11-22 16:19: Team starts bugfix implementation * 2023-11-22 17:40: Fix deployed to production * 2023-11-22 18:40: Last cached error response expired * 2023-11-22 18:40: **SERVICE DEGRADATION ENDS**
2023-11-21 17:40 -/json/ and -/main_colors/ operations returning 400 status
Report: "CDN"
Last updateThis incident has been resolved.
We are continuing to monitor for any further issues.
We are continuing to monitor for any further issues.
We've observed heightened latency and error rates for uncached requests to our CDN and image processing API from 6:00 to 6:45 UTC. This was primarily due to a surge in server load and a deviation in our capacity scaling mechanism. Currently we still experienced heightened load, while capacity scaling mechanism was fixed.
Report: "Service degradation"
Last updateWe have experienced a service degradation from 05:08 to 05:10 UTC. The source of the problem was identified and we are working on the fix for the future.
Report: "Higher latencies of from_url uploads"
Last updateThis incident has been resolved.
A fix has been implemented and we are monitoring the results.
We’re experiencing higher latencies of from_url uploads. Direct uploads are fully functional. We’ve identified the source of the problem and are working on the fix.
Report: "Upload degradation from cloud services"
Last updateThis incident has been resolved.
A fix has been implemented and we are monitoring the results.
The issue has been identified and a fix is being implemented.
We’re experiencing service degradation of uploads from cloud services (e.g. Facebook, Google Drive). We're currently investigating the issue. Direct uploads are fully functional.
Report: "Higher latencies of from_url uploads"
Last updateFrom 12:29 to 13:31 UTC we’ve experienced higher latencies of from_url uploads. Direct uploads were fully functional. We’ve identified the source of the problem, eliminated it and are monitoring the situation. The service is fully functional now.
Report: "Elevated CDN 5xx Errors"
Last updateBetween 14:30-14:51 UTC customers may have experienced elevated levels of errors.
Report: "Webhooks operational issue"
Last updateThis incident has been resolved.
A fix has been implemented and we are monitoring the results.
We are experiencing elevated error rates for Webhooks service. We have identified root cause and we are actively working towards recovery.
Report: "Issue with DNS resolving for *.ucr.io domains"
Last updateThis incident has been resolved.
The problems with DNS resolving recovered. We are still monitoring.
We are continuing to investigate this issue.
We are currently investigating the issue with DNS resolving.
Report: "DNS issues"
Last updateNo more issues with DNS resolving were detected.
A fix has been implemented and we are monitoring the results.
The issue has been identified and a fix is being implemented.
We are experiencing issues with DNS resolving of *.uploadcare.com
Report: "Elevated CDN 5xx Errors"
Last updateBetween 16:38-16:43 UTC customers may have experienced elevated levels of errors.
Report: "Webhook issues for SVG files"
Last updateThis incident has been resolved. All webhooks have been delivered as expected.
A fix has been implemented and we are monitoring the results.
We're working on the fix.
We're experiencing issues with webhook delivery for SVG uploads. The main Upload API remains fully functional.
Report: "Partial degradation of from_url uploads"
Last updateFrom 15:44 to 15:55 UTC we had bad configuration deployment resulting in partial degradation of our uploads service. The service is fully functional now.
Starting at 15:44 UTC we’ve experienced partial degradation of our uploads. We’ve identified the source of problems, implemented fixes and are monitoring the situation.
We're experiencing issues with from_url uploads.
Report: "Partial degradation on uploads, api"
Last updateThis incident has been resolved.
We have experienced issues with our uploads, api systems from 7:51 to 7:56 UTC. We have identified the source of problems, implemented the fix and are monitoring the situation.
Report: "Partial degradation of image processing and file delivery"
Last updateFrom 8:20 to 9:20 UTC we’ve experienced partial outage of our image processing and file delivery due to degradation of our storage subsystem. The issue is resolved. All systems are working properly now.
The issue is resolved. We are monitoring the situation.
We have identified the issue.
We have identified the issue.
We're experiencing issues with image processing and file delivery.
Report: "Video Processing System Maintenance"
Last updateThis incident has been resolved.
Video processing vendor is performing database maintenance between 6 am and 11 am UTC. They're trying to minimize the impact on their service.
Report: "Website partial outage."
Last updateThis incident has been resolved.
Still waiting for Netlify to fix things on their end. Core Uploadcare services are not impacted. Uploads, REST API, CDN, document/video conversion engines are working.
Due to our vendor issues, website is partially down.
Report: "Higher latency and increased error rate on CDN and upload API"
Last updateThis incident has been resolved.
This incident has been resolved.
From 07:25 to 7:45 UTC we've experienced higher latency and increased error rate on AWS S3 resulting in partial degradation of our content delivery service and upload API. We are monitoring the situation.
Report: "Expired certificate on ucarecdn.com"
Last update# What happened On 19th July 2019 at 15:30 UTC certificate used to serve traffic from [ucarecdn.com](http://ucarecdn.com) and [www.ucarecdn.com](http://www.ucarecdn.com) has expired. All HTTPS traffic to these domains effectively stopped. We were able to quickly \(within minutes\) redirect [www.ucarecdn.com](http://www.ucarecdn.com) traffic to alternative CDN provider with proper certificate installed. It took us approximately 105 minutes since start of the incident to fix the issue with [ucarecdn.com](http://ucarecdn.com). 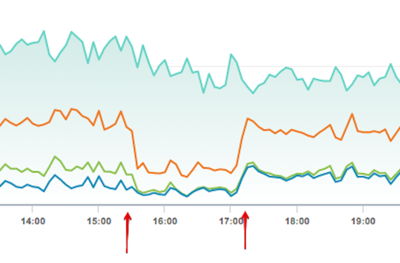 # Why that happened 1. Our CDN partner's certificate management system failed to renew the certificate in question and needed an input from our team. 2. It did sent an email 5 days prior to expiration requesting manual input. 3. This email wasn't noticed, because it was sent to a team member that was off the grid on vacation. # What we should do to improve 1. Change notification system settings, so any issues with certificates with our CDN partners are sent to a team, not a person \[done\] 2. Use 3rd party service to monitor certificate expiration and other settings \[done\] 3. Use CDN partner's APIs to actively and automatically monitor certificates \[in progress\] 4. Create an service that could be used to quickly redirect [ucarecdn.com](http://ucarecdn.com) traffic to backup CDNs in case of any issues with the main one \(not only due to certificates\)
This incident has been resolved.
A fix has been implemented and we are monitoring the results.
We are continuing to work on a fix for this issue.
The issue has been identified and a fix is being implemented.
Report: "REST API partial outage"
Last updateThis incident has been resolved.
Starting at 09:20 UTC we've experienced partial outage of our REST API. We've identified the source of problems, deployed fixes and are monitoring the situation.
Report: "Upload service degradation."
Last updateOn December 12, we had a degradation of our Upload API. Most users were unable to upload files for 3 hours 11 minutes between Dec 12, 22:39 GMT and Dec 13, 01:50 GMT. ## What happened Requests to Upload API were either handled extremely slowly or \(most of them\) rejected by our web workers. Scaling up our Upload API fleet didn't help. ## What really happened Further investigation revealed that: — Slow requests were consuming all available web workers and without available workers requests were rejected by nginx. — Handled requests were slow due to constant database locks on one database table. — Database locks were caused by dramatical change of tracked usage statistics \(change of project settings by one of our largest customers\). We've spent most of the time during incident on investigation and figuring our what is happening. Actual DB load was average, and DB was wrongly dismissed as source of issues at first. Once we've the root cause, the fix was trivial and took minutes to implement and deploy. ## What we have done We turned off usage tracking for particular customer. ## What we will do — Refactor statistic tracking, so it does not affect our core service. — Add more specific monitors to our DB, so we could identify problems of similar nature much faster.
This incident has been resolved.
A fix has been implemented and we are monitoring the results.
The issue has been identified and a fix is being implemented.
We are continuing to investigate this issue.
We're experiencing issues with out Upload API.
Report: "Partial Upload and CDN outage"
Last updateWe've experienced a partial outage due to issues at AWS, our network infrastructure provider. Starting from approximately 20:07 till 20:25 UTC there was an increased error rates for Upload API and on CDN origins. Due to the nature of the issue, our error reporting systems didn't notice Upload API problems: * all reported metrics were OK * there were no anomalies like drop in upload success rates or peaks in upload error rates We were only aware of CDN origin problems until some of our customers reported issues with Uploading. Underlying issue is quoted below: > Instance launch errors and connectivity issues > > 01:49 PM PDT Between 1:06 PM and 1:33 PM PDT we experienced increased error rates for new instance launches and intermittent network connectivity issues for some running instances in a single Availability Zone in the US-EAST-1 Region. The issue has been resolved and the service is operating normally
We've experienced a partial outage. Starting from approximately 20:07 till 20:25 UTC there was an increased error rates for Upload API and on CDN origins.
Report: "Upload API downtime"
Last updateThis incident has been resolved.
The was 8 minutes downtime starting from 18:21 UTC. What happened: We're trying to mitigate Roscomnadzor's carpet bombing our Russian clients and end users. As one of the measures we've changed our Load Balancing settings but missed one critical config setting that caused the downtime during our regular code deployment. We've fixed the setting and are monitoring the situation.
Report: "Increased CDN error rates"
Last updateThis incident has been resolved.
The issues were caused by network connectivity problems in AWS east-1 region.
Our CDN origin fleet is experiencing increased error rate.
Report: "Increased REST API error rates"
Last updateWe've encountered increased error rates on our REST API endpoints. This resulted in reduced reported uptime. In fact, even though the uptime suffered it wasn't as bad as reported. What happened: - from February 25 22:00 UTC to February 26 05:50 UTC error rates on REST API endpoints were increased Why that happened: - one of the machines in REST API fleet ran out of memory - due to OOM, the machine was unable to handle any incoming requests - misconfigured health check prevented load balancer from getting rid of the failing machine - part of all requests, including Pingdom (that reports our uptime) ones, was sent to that failing machine What we've done: - tracked down and terminated the failing machine - fixed health check configuration
Report: "Increased error rate for Upload API"
Last updateThis incident has been resolved.
Our diagnostic tools show that all subsystems are back to normal. We continue monitoring of the situation.
Error rates are decreasing.
Appears that increased error rate is connected with increased error rate for S3.
We are currently investigating this issue.
Report: "Upload API was down from 03:04 to 05:16"
Last updateDue to error in infrastructure configuration, our queue responsible for uploading files was not working properly.
Report: "File copying is now working"
Last updateWe have found and fixed the issue with backing up of stored files to S3. All files that were not backed up during the incident will be backed up eventually. Automatic copying of uploaded files to S3 buckets (Custom storage) was not affected by the issue.
A fix has been implemented and we are monitoring the results.
Automatic file copying is not working at the moment, we're investigating the cause of this.
Report: "Uploadcare services have degraded performance"
Last updateCurrently, Uploadcare service is fully working. We continue monitoring the situation closely.
Upload API is up again. We continue monitoring all components.
Upload API went down.
AWS Autoscaling is still down, we're deploying new instances manually.
AWS has reported that everything is green. We're working on recovering affected Uploadcare components. Currently, everything should work but higher latency and error rate are expected.
AWS has fixed working with existing S3 objects, so CDN and subset of REST API are working at the moment. More details on AWS status: https://status.aws.amazon.com/
AWS S3 is experiencing increased error rates that results in all of our buckets going AWOL.
Our CDN is down. Investigating.
Report: "Increased error rate on CDN"
Last updateCDN provider switch resolved the issue and went smoothly.
CDN provider switch is complete. We continue monitoring the situation.
We're experiencing increased error rates on our CDN. Switching to another CDN provider.
Report: "REST API Increased latency."
Last updateThe issue is resolved. REST API latency is back to normal.
Since 09:30 UTC we're experiencing an increased latency for our REST API endpoints. We've found the reason and are working on resolving the issue.
Report: "Upload API is down."
Last updateThis incident has been resolved.
Upload API is not working. The problem is identified and the fix is being deployed.
Report: "Partial CDN service degradation for Russian users."
Last updateThis incident has been resolved.
We've experienced CDN service degradation for some of our end users that get content from edge servers in Moscow, Russia. We've identified and resolved the issue. Currently, we're monitoring the situation. The incident took place between 19:00 and 22:00 UTC.
Report: "Increased error rate on REST API"
Last updateThis incident has been resolved.
We've fixed the issue and continue monitoring the REST API servers.
We are currently investigating this issue.
Report: "Direct uploads to S3 buckets"
Last updateThe fix is deployed to our upload servers.
Currently direct uploads to clients' buckets located in regions other than 'standart' don't work. We've identified the cause of the issue and are working on the fix.
Report: "Increased error rate during uploads."
Last updateWe've found and fixed the issue that was causing upload latency.
We're seeing increased error rate and latency during file upload. Investigating.
Report: "Increased error rate for group files on CDN"
Last updateThis incident has been resolved.
Due to AWS service degradation we're experiencing increased error rate for "file in group" on CDN.