
Historical record of incidents for Python Infrastructure
Report: "PyPI Search Index Degraded"
Last updateThe PyPI search index has degraded and is not returning results. A reindexing job has begun, and results will be available once it completes.
Report: "PyPI Partial Outage"
Last updateWe have not seen a return of the traffic that caused this incident after removing the temporary block. We will open a new incident if we need to take action again.
We have removed the temporary block and are continuing to monitor.
Our block is in place and systems are stable, but we are not satisfied with having to block such a generic user-agent. If you are aware of a system that began a mass crawl of PyPI's JSON release endpoints starting at around 22:05 UTC 2025-05-25, please contact admin@pypi.org.
We have identified a flood of requests from a cluster using the `python-requests/2.32.3` User-Agent, and attempting to hit all JSON project/releasese en masse. This causes excessive cache misses, which are overwhelming our backends. A temporary block has been put in place.
We have identified a large increase in CDN cache misses causing excess load on our backends. We are working to determine the reason for this increase.
We are working to investigate a partial outage in the PyPI backends.
Report: "PyPI Partial Outage"
Last updateWe are working to investigate a partial outage in the PyPI backends.
Report: "PyPI Elevated Error Rates"
Last updateThis incident is resolved. We're going to do some further investigation to understand what led to the lock contention.
The locking process has been terminated and we're monitoring as things recover.
We've identified an issue with database contention arising from locking.
We're investigating elevated error rates for pypi.org
Report: "PyPI Elevated Error Rates"
Last updateWe're investigating elevated error rates for pypi.org
Report: "PyPI Simple and JSON API Outage"
Last updateThis incident has been resolved.
Errors have subsided, and we are monitoring as things continue to recover.
We've increased capacity in the worker pools that service /simple and /json and are monitoring as things recover.
We are working to resolve an outage impacting our /simple and /json apis.
Report: "PyPI Simple and JSON API Outage"
Last updateWe are working to resolve an outage impacting our /simple and /json apis.
Report: "Download file corruption"
Last updateThis incident has been resolved.
We are continuing to monitor for any further issues.
Our CDN provider has reported that the node in question has been removed from service. We are monitoring for continued reports.
This issue appears to be isolated to a single edge node in our CDN provider's network. They have validated the issue and are working to resolve.
We are investigating issues with files from files.pythonhosted.org being served with corrupted data. A support ticket has been opened with our CDN provider and we are awaiting their response.
Report: "Infrastructure Outage"
Last updateThis incident has been resolved.
We have begun seeing recovery across all services as of 14:44 UTC, we are monitoring for stability and ensuring all services are healthy.
We are continuing to work on a fix for this issue.
We are continuing to work on a fix for this issue.
Private networking in our datacenter for these services is currently intermittent, we have opened a ticket with the provider requesting assistance.
We are continuing to investigate this issue.
We are continuing to investigate this issue.
We are currently investigating an infrastructure outage impacting python.org/downloads backends, docs.python.org backends, bugs.python.org backends, wiki.python.org backends, as well as other services.
Report: "PyPI Simple Index Timing Out"
Last update**What happened?** PyPI experienced an outage which resulted in serving 500-level responses for certain requests, including requests to a subset of the [Simple Repository API](https://peps.python.org/pep-0503/), from approximately 19:00:00 UTC to 20:15:00 UTC. As a result, some packages were uninstallable during this period. While such outages are not entirely uncommon and generally easy to recover from, this outage was more severe due to PyPI becoming un-deployable as a result of its own outage. **Impact** At its peak, PyPI served errors at approximately 25 responses per second and in total nearly 100K requests during this ~1hr 15m period resulted in an error. This represents approximately 0.04% of usual traffic to the affected services. **Background** PyPI is served by a Python web application named ‘Warehouse’, with several dependencies on Python packages that are hosted on PyPI. As part of the deployment pipeline, Warehouse and its dependencies are built into a series of container images that are ultimately deployed into a container orchestration service. At the time of the incident, PyPI contributors were working on adding new functionality, which included introducing a new service to the service layer used with PyPI’s web framework. While the actual details of this new functionality is unrelated, a misconfiguration of this new service resulted in views that depended on this service failing to successfully serve a response, which was missed by PyPI’s unit test suite and by manual testing of the feature branch. **Investigation** PyPI administrators were notified of a production error approximately 10 minutes after it was introduced, and immediately after a faulty request was served: * 2024-08-21T18:48:29 UTC - The feature branch is merged into the \`main\` branch of the Warehouse repository * 2024-08-21T18:55:42 UTC - The container image is built and deployed to production * 2024-08-21T18:58:37 UTC - PyPI admins are notified of an exception in production affecting a Simple Repository API view At this point, PyPI administrators began working on a fix. **Root Causes and Trigger** PyPI administrators immediately determined that the recent merge was at fault due to timing and clear signals from the error observed. As a result of PyPI’s container orchestration and deployment service not explicitly supporting rollbacks, issues like this are generally resolved by introducing a new pull request which reverts the problematic commit, which in turn is merged and [deployed.](http://deployed.In) In this instance, a revert commit was prepared, however the decision was made to wait for a forward fix to be prepared instead. This was partly because it was thought that this fix would be a trivial change and could be prepared as quickly as a revert, thus saving time overall. However, additionally, the introduction of the new feature included a database migration which had already been applied in production. This migration could not be reverted simply by reverting the commit, as deployment would fail when it would attempt to bring the database up to date with the migration history, and find that the current migration version was no longer present. This instead would require an additional migration to migrate the database forwards to a state that would be compatible with the reverted commit, which would potentially take more time than introducing a fix. The fix was prepared, merged and deployed, however it contained an additional issue that resulted in it not ultimately resolving the root cause. An additional pull request to rectify the issue with the forward fix was prepared. At this time, PyPI administrators noted that PyPI’s CI/CD suite was failing to build the containers required to run the test suite on new pull requests, due to the \`/simple\` detail page for one of PyPI’s dependencies being unresolvable due to the outage. As a result, the team decided to pursue a full revert of the feature instead, hoping to leverage our container layer cache to ensure that external requests to PyPI would not be necessary to build. An additional pull request to fully revert the faulty commit was prepared. While the container image build on the new PR was successful, a CI/CD check which did not use the container image, namely a check that ensures Warehouse’s dependency lock files are up-to-date, failed due to the outage. PyPI administrators attempted disabling the required status of these checks in branch protection for the repository, however the failed dependency check caused the remaining tests to be canceled before completion, which prevented the deployment pipeline from picking up on the new commit and triggering a deployment. At this time, PyPI administrators determined that overriding the build/deploy service to manually revert the deployed container image back to a known good image, bypassing the release phase that included migrations, was required. **Mitigation** Mitigation required bypassing PyPI’s build and deploy pipeline to manually re-deploy a previously built image, without running the release phase which included migrations. This allowed PyPI to successfully respond to previously failing requests, allowing the reverted pull request to build and be deployed, fully resolving the issue in production. * 2024-08-21T20:17:58 UTC - The revert was fully deployed to production and errors subsided Additionally, after the production incident was resolved, it was determined that although the final deployment to TestPyPI had been reported as successful, it had not succeeded due to the database migration failing to get a lock, highlighting that there was additionally a logic error in our deployment reporting when deployments fail. **Lessons Learned** * Until additional protections are in place, when an outage affects \`/simple\`, reverts must be immediate or they run the risk of requiring manual intervention. * It is clear that a lack of functional testing is a gap in assurances against production outages. **Things That Went Well** * Maintaining cached container image layers proved potentially useful for recovering from issues where new container images could not be built due to the outage. **Things That Went Poorly** * PyPI used to maintain a mirror of itself on a third-party service to prevent incidents like this, however this is no longer used due to maintenance of the mirror becoming an issue due to on-disk size. * The decision to not revert and fix forward instead proved to not work out. While the additional time to do the additional work to revert could have still resulted in a stuck merge, waiting for the forward fix, which had additional issues, resulted in enough time passing for one of PyPI’s dependencies to be affected by the outage. * A popular dependency, which was also a Warehouse sub-dependency, quickly fell out of cache. PyPI’s CDN is configured to serve stale responses while it revalidates for 5 minutes, and to serve stale responses while the backends are returning errors for 1 day, so the CDN should not have served an error for any of these pages. * The lack of a mirror and a production dependency on PyPI allowed for an ‘ouroboros’ style paradoxical outage that could not be resolved by a simple revert. * A subset of CI/CD checks in the critical path to deployment reach out to PyPI directly as part of their tests, and as a result they will likely fail in conditions like this outage. * Failing CI/CD checks that were not strictly required by branch protection rules were preventing the deployment pipeline from proceeding with the deployment due to setting \`cancel-in-progress: true\` on the parent workflow, causing the workflow to fail when they failed or were canceled. * The Warehouse codebase has extensive unit testing which depends on stubbing/mocking which masked the root cause. The codebase only recently gained the ability to perform functional testing, but the problematic PR did not add additional functional tests, and the limited functional testing that did exist missed this issue. **Where We Got Lucky** * At the time of the incident, all of PyPI’s administrators were online and able to contribute towards mitigating the outage, including the sole administrator that was capable of performing the manual rollback. **Action Items** * Determine why the sub-dependency fell out of cache more quickly than expected based on the CDN configuration, and how that could have been prevented. * Add functional testing to cover the Simple Repository API, with a focus on critical code paths that can cause similar outages. * Update the deployment pipeline to correctly report on deployment status. * Introduce rollback functionality for the deployment pipeline so that a rollback does not require manual intervention or specific knowledge. * Re-introduce a mirror \(either static or a caching proxy\) for PyPI that would not be affected by production outages. * Revisit the CI/CD dependency check and determine how it be hardened against a production outage to not block a deployment.
This incident has been resolved.
An error serving /simple requests has caused timeouts for some requests. We have identified the issue and are working on a revert.
Report: "Issue with uploads"
Last updateUploads are now being accepted properly.
A fix has been implemented and we are monitoring the results.
The issue has been identified and a fix is being implemented.
We are currently investigating an issue with PyPI uploads causing uploads to fail.
Report: "PyPI Backend Outage"
Last updateThis incident has been resolved.
We are currently investigating an issue with the PyPI backend due to a recent deploy.
Report: "PyPI Database Upgrades"
Last updateThis maintenance is complete.
We are performing upgrades to PyPI's database storage which may impact performance and availability of the service as they rollout.
Report: "PyPI Database Upgrades"
Last updateAll maintenance is complete and telemetry around database and application performance have stabilized. This incident is complete.
All upgrade steps are complete and performance is stabilizing. A final maintenance task is taking place in the background which will minimally impact performance until it is complete.
We are in the final steps of the upgrade and should see performance and availability stabilize in the next 30 minutes.
Underlying upgrades are complete, we are running database statistics updates to optimize performance.
We will be performing database maintenance including version upgrades and storage re-configuration. This will result in several brief outages for the service.
Report: "Outage in python.org and us.pycon.org"
Last updateThis incident has been resolved.
A cascading failure due to an expired certificate led to this outage. The certificate has been expired and systems are coming back online.
An outage in our infrastructure is impacting availability of us.pycon.org and python.org
Report: "PyPI New User Registration and New Project Creation Temporarily Suspended."
Last updateThis incident has been resolved.
We have temporarily suspended new project creation and new user registration to mitigate an ongoing malware upload campaign.
Report: "PyPI workers currently paused"
Last updateThis incident has been resolved.
Workers have been restarted and are clearing backlog of enqueued tasks.
A maintenance event requires us to pause our workers, which will delay cache purges and email delivery. We anticipate this will persist for up to 30 minutes.
Report: "Site wide issue in PSF Infrastructure"
Last updateThis incident has been resolved.
Our new internal CA has been rolled out across the infrastructure and we are monitoring for remaining service impact.
Our internal Certificate Authority certificate has expired causing cascading outages across multiple services. An updated CA has been created and we are working to roll it out to restore service.
A site wide issue is impacting many services hosted in the PSF infrastructure.
Report: "bugs.python.org under maintenance"
Last updateMaintenance is complete.
Maintenance and migration is complete. DNS may take some time to propagate. We will monitor as that occurs.
bugs.python.org (and bugs.jython.org, and issues.roundup-tracker.org) is currently under maintenance.
Report: "PyPI new user registration temporarily suspended"
Last updateNew user registrations are now permitted.
New user registration on PyPI is temporarily suspended. The volume of malicious users and malicious projects being created on the index in the past week has outpaced our ability to respond to it in a timely fashion, especially with multiple PyPI administrators on leave.
Report: "PyPI new user registration temporarily suspended"
Last updateThis incident has been resolved.
New user registration on PyPI is temporarily suspended. The volume of malicious users and malicious projects being created on the index in the past week has outpaced our ability to respond to it in a timely fashion, especially with multiple PyPI administrators on leave.
Report: "Database Storage Latencies"
Last updateThis incident has been resolved.
A burst balance for our cloud storage disks that host our databases was exhausted. We are going to migrate to storage that will allow us to respond by adding more IOPS.
We are investigating and responding to widespread issues with databases in our infrastructure showing poor performance due to cloud block storage.
Report: "Reports of failed connections from us-east-2"
Last updateThis incident has been resolved.
Fastly has routed traffic away from an impacted point of presence. We will monitor for further impact.
We're receiving reports from users that attempts to download packages from PyPIs files archive may be failing when clients use IPv6 as their transport. Our network provider Fastly is also investigating the issue, see their status page: https://www.fastlystatus.com/incident/376079
Report: "Intermittent outages in PyPI backends."
Last updateThis incident has been resolved.
The migration has been completed and we are monitoring to ensure stability.
A slow migration PyPI admins are attempting to apply is causing database contention leading to intermittent outages in the PyPI backends. We are working on mitigating the impact to end users.
Report: "Some PyPI web requests failing."
Last updateThis incident has been resolved.
The revert has been deployed and we are monitoring the result.
We have initiated a rollback of the change that introduced this outage.
An update to our database connection library has caused some web requests including uploads to fail. We have identified the issue and are working to resolve.
Report: "Object storage provider outage"
Last updateThis incident has been resolved.
Our mitigation has decreased overall latencies, but they remain elevated over normal operation. As our provider's service recovers we expect to see a return to baseline.
We are also implementing our own change to guard against excessive latencies from the provider.
We're in communication with the object storage provider and are waiting for them to rollout a fix.
We have identified an issue that is impacting latencies for files.pythonhosted.org, resulting in timeouts for a portion of requests.
We are currently investigating an issue with our object storage provider.
Report: "PyPI new user and new project registrations temporarily suspended."
Last updateSuspension has been lifted.
New user and new project name registration on PyPI is temporarily suspended. The volume of malicious users and malicious projects being created on the index in the past week has outpaced our ability to respond to it in a timely fashion, especially with multiple PyPI administrators on leave. While we re-group over the weekend, new user and new project registration is temporarily suspended.
Report: "File Uploads returning 500 responses"
Last updateThis incident has been resolved.
One of our providers is returning 500 responses during new package file uploads. They have completed their work, and errors should be subsiding. We are monitoring the situation.
Report: "PyPI uploads are failing"
Last updateThis incident has been resolved.
Our object storage provider has recovered from the outage and we are monitoring for any regressions.
Our object storage provider is currently experiencing an outage, causing PyPI uploads to fail.
Report: "Uploads are failing intermittently"
Last updateWe have seen errors subside over the last 16 hours, and uploads are succeeding as usual.
We are continuing to monitor for any further issues.
The upstream provider has identified the issue as being resolved and we have seen failures subside over the last hour. We are continuing to monitor for regressions.
We are still observing intermittent upload failures and have contacted our upstream provider for support.
We are currently investigating an intermittent outage with our upstream object storage provider, causing uploads for new releases to fail intermittently with a "503: Service Unavailable".
Report: "python.org backend outage"
Last updateThis incident has been resolved.
A fix has been implemented and we are monitoring the results.
We are working to resolve a backend outage on python.org due to an outage in our search infrastructure.
Report: "PyPI Emails Not Sending"
Last update## Summary At 20:36 UTC on 2023-03-17, PyPI’s email provider enforced a suspension against our account. After our remediation efforts and response, our account was restored at 00:36 UTC 2023-03-18. In response, the PyPI Administrators did the following: * Audited our email logs, including delivery and complaint status to determine the underlying factor that had led to our suspension. * Rolled out updates to our signup form to mitigate the behavior that was leading to complaint emails. * Notified our provider of our remediation efforts * Rolled out updates to our retry logic to report exceptions in tasks that were being swallowed by retry logic. The following was determined in the course of our response: * Our monitoring was blind to email failures due to retry logic swallowing the apparently transient errors, so response was delayed by nearly 15 minutes. * An account review was initiated 2021-09-04 by our provider due to a marginal complaint rate. This had been considered at the time and PyPI Administrators somewhat ironically began sending more valid notification emails whenever reasonable to bump our reputation. PyPI’s email sending pattern is consistently low volume aside from routine account signup and password resets. After rolling these changes out, it wasn’t clear if “enough” had been done and it eventually fell out of the collective mind of the PyPI administrators. * Our China accessible \(not reCaptcha as it is blocked there\) bot detection honeypot had been letting just enough bad signups through to maintain a 0.6% complaint rate from victims of whatever malfeasance the bots were enabling. ## Impact Actions that triggered emails during the outage window from 2023-03-17T20:36Z - 2023-03-18T00:36Z were delayed in sending . All emails enqueued during that time were delivered by retry before 2023-03-18T01:00Z \(up to 4.5 hours delayed\). ## Timeline * 2018-03-08: [Issue](https://github.com/pypi/warehouse/issues/3174) filed regarding inability to signup for PyPI from China due to reCaptcha being blocked. * 2018-03-21: Implementation of a relaxed bot detection in place of reCaptcha [merged](https://github.com/pypi/warehouse/pull/3339#event-1534405160) and deployed. * 2021-09-04: Report of account review received from our email provider. * 2023-03-17: Account suspension enforced by our email provider. * 2023-03-17: reCaptcha [re-enabled](https://github.com/pypi/warehouse/pull/13232) for our signup form. * 2023-03-17: Error reporting for exceptions in failed tasks [merged](https://github.com/pypi/warehouse/pull/13236) and deployed. ## Future Work * Investigate bot detection mechanisms that are robust _and_ available to users in China. * Research backup mail providers for failover. * Send more email to retain reputation.
Our vendor has reinstated our sending ability after reviewing our remediation. Emails that were enqueued during the outage will send over the next 1-2 hours.
We have validated that failed email sends are queuing for delivery when our account suspension is lifted. For the moment we are holding off on mitigating by failing over to another provider. If we do not see resolution in 12 hours we will begin work to add another provider as a failover. Regardless we plan to reassess our resilience against email provider outages in the next work week.
We have submitted our response with remediation efforts to the provider and are awaiting their response/resolution. Detail: PyPI replaced reCaptcha on our signup form with a less robust form of automation defense in 2018 due to reports from users in China not being able to sign up. We have temporarily re-enabled reCaptcha in order to reduce inbox-bombing signups against PyPI. We will readdress ways to improve our defenses in the future, without needlessly denying access to users in China to PyPI.
We have identified the contributing factor that led to our complaint rate going above the acceptable threshold of our provider and are working to implement a fix that will satisfy their requirements.
We are working through the remediation process requested by our provider.
All emails sent by PyPI are currently not being sent. Our email provider has suspended our account. We are currently determining how to proceed.
Report: "PyPI File Hosting Latencies and Timeouts"
Last updateThis incident has been resolved.
We're seeing improvements after reports from our backend providers that their incident is resolved.
We're continuing to investigate with our CDN, but found a potentially related outage published by our backend that we are now tracking as well.
We are working with our CDN provider to determine what is contributing to these latencies.
We are investigating issues with files.pythonhosted.org causing larger files to experience large latencies and timeouts.
Report: "PyPI Dictionary Attack"
Last updateThis incident has been resolved.
Beginning on Nov 6th, 2022, PyPI began to become inundated with failed authentication attempts due to a dictionary attack (https://en.wikipedia.org/wiki/Dictionary_attack). At its peak, the attack was attempting more than 260K passwords per hour, and at the time of writing has resulted in more than 6 million invalid authentication attempts. The attacker used a large pool of IP addresses to cycle through multiple IPs as each one reached our ratelimit for authentication failures. The attacker specifically used PyPI’s ‘basic’ HTTP authentication methods associated with our upload endpoint. PyPI integrates with the Have I Been Pwned (HIBP) API (https://haveibeenpwned.com/API/v2) to prevent dictionary and credential stuffing attacks. Four times during the period of this attack, PyPI used the HIBP API to determine that a compromised password was being used to log into a user’s account, making it likely that the attacker was using a set of leaked passwords that HIBP includes in its dataset. For comparison, in the two weeks prior to the start of the attack, PyPI identified the usage of 16 compromised passwords via HIBP. As a result, in each of these occurrences, PyPI prevented the authentication attempt from succeeding, forcing the user’s password to be reset, and notifying the user. Due to insufficient metrics at the time, we are unable to determine what proportion of these login attempts with compromised passwords were likely legitimate, and what percentage were from IPs participating in the dictionary attack. At this time, we have determined that no successful logins to legitimate user accounts have been performed from requests originating from IP addresses participating in the dictionary attack. As a result of this attack, PyPI has made a number of changes to improve our ability to respond to such an attack: - Added a new user event type for successful ‘basic’ HTTP authentication logins - Added a new user event type for detection of compromised passwords via HIBP - Added new moderation tools to track the occurrence of abuse attempts grouped by IP address At the time of writing, the attack has temporarily abated, as it has a few times over the past week. The PyPI volunteer team will continue to monitor for changes, as well as for potentially compromised accounts.
Report: "PyPI Backends are unavailable."
Last update## Summary The cluster that hosts PyPI’s backends as well as multiple ancillary services experienced an outage during maintenance that interrupted access to services over HTTPS. ## Details From 2022-10-24 14:43 UTC until 2022-10-24 15:03 UTC, PyPI’s backends were not accessible over HTTPS. This interfered with our CDNs ability to fetch pages, made uploads to [uploads.pypi.org](http://uploads.pypi.org) impossible, and interrupted other services such as our legacy file redirect service. PyPI services run as deployments in a Kubernetes cluster and are exposed via Ingress with the AWS Elastic Load Balancer \(ELB\) integration. The TLS certificate that this load balancer uses is managed via Amazon’s Certificate Manager \(ACM\). When initially deploying our Kubernetes cluster, the Ingress managed ELB was configured to use an existing ACM TLS certificate. Earlier today, regular maintenance of our Kubernetes cluster required a rolling restart of all nodes in the cluster to distribute upgrades and new configurations to all nodes. During this rolling restart as the Kubernetes API server hosts were deployed, Kubernetes validated and refreshed the Ingress configurations we had previously defined. Since the most recent rolling upgrade, an additional hostname was needed for PyPI’s Ingress. PyPI administrators created a new ACM TLS certificate including that hostname and updated the Ingress managed ELB to use this new certificate. As a result, the new Kubernetes API servers were unable to find the previous ACM TLS certificate and disabled the HTTPS listener for the Ingress configuration that serves PyPI and associated services as they came online. Once identified, the PyPI admins updated the Ingress configuration to point to the new ACM TLS certificate and Kubernetes restored the HTTPS listener on the Ingress managed ELB, restoring access to all services. ## Mitigation We will investigate mechanisms by which the hostnames needed on ACM TLS certificates for PyPI’s Ingress configurations can be managed via Kubernetes resources rather than manually via the AWS console. By managing resources all via the Kubernetes API, drift between desired state and reality will be less likely to occur and surface during similar maintenance in the future.
This incident has been resolved.
We have identified and resolved the reason for the outage and are monitoring to ensure it remains stable.
The backend that hosts PyPI and associated services is experiencing a major outage, we are investigating.
Report: "PyPI UI missing CSS"
Last updateAll CSS appears to be loading, we will investigate what occurred that caused CSS to fail to load during deployment.
Some users experienced missing CSS files during a deployment of PyPI. Those files now appear to be serving, we are monitoring for further reports.
We are currently investigating this issue.
Report: "TestPyPI Maintenance"
Last updateThis maintenance is complete. Please file an issue at https://github.com/pypa/pypi-support/issues/new?assignees=&labels=network&template=access-issues.yml if you experience issues with test.pypi.org after this migration.
TestPyPI may be unaccessible for up to an hour while we complete migration of the CDN configurations. Services may also be impacted after the migration due to changes in the configuration to better match PyPI.org. We will be monitoring throughout and after these changes.
Report: "TestPyPI under maintenance."
Last updateThis incident has been resolved.
https://test.pypi.org's infrastructure is currently under maintenance. File downloads may be impacted while we migrate our CDN for the service.
Report: "docs.python.org backend down"
Last updateThis incident has been resolved.
The underlying cause is that the host is running on a host with degraded storage performance. We will be taking the host back offline to migrate it to a new underlying system.
Host is back online and we are monitoring the status of the services it backs.
Our CDN will continue to serve pages that are cached, but some docs.python.org URLs will not be able to load. In the event of cache expiry some pages that were previously cached may become unavailable.
The backends for docs.python.org are currently unavailable. They became unresponsive at approximately 12:00 UTC and we have been unable to bring the cloud server back online via administration panel. We are working with our hosting provider to bring the host back online.
Report: "Notice: PyPI Mass CDN Purge"
Last updateOur CDN hit rate and latencies have recovered, this event is now resolved.
Error rates have returned to baseline, and latencies continue to return to normal across our services. We will continue to monitor as the database upgrades complete and caches re-fill.
Our backends have begun to stabilize as the caches are refilled. During the peak of the backend traffic from our CDN we recognized a few bottlenecks in our database layer and have provisioned additional storage IOPs in order to reduce impact of surges in the future.
Purge All has been issued and we are monitoring as the backends attempt to meet the request volume. We anticipate that the service will continue to stabilize and reach steady state over the next 30-90 minutes.
In order to resolve an issue in our CDN cache caused by a misconfiguration of Surrogate-Keys, PyPI will need to issue a "Purge All" of our CDN to clear out lingering cached objects that are not accessible to purge individually. This purge is very likely to impact performance when accessing PyPI for some time. In order to avoid purges like this in the future, our backends have been configured with Surrogate-Keys that will at least allow us to purge specific endpoint types rather than the entire service.
Report: "PyPI Outage 2022-07-28 18:46-18:53 UTC"
Last updatePyPI experienced an outage in its backends from 18:46-18:53 UTC on 2022-07-28. This outage stemmed from a cascading failure in the backend infrastructure that disrupted the management layer that deploys and secures PyPI's application servers. ## Details Beginning at 17:24 UTC multiple cloud instances that are members of the Kubernetes cluster that PyPI runs on were automatically replaced by the provider due to an unknown failure. By 18:20 UTC all instances were replaced and healthy as part of the Kubernetes cluster. This replacement event caused the system to reshuffle _many_ pods which impacted both our Consul and Vault clusters inside Kubernetes. Both services were restarted across new nodes. At 18:23 UTC the first alert was delivered to PSF Infrastructure to notify that at least one Vault container was down and required unsealing to come back online. Upon investigation it was determined that all Vault containers in the cluster were unavailable and that the Consul containers were unable to establish a new leader. The responding Infrastructure Team member worked to bring Consul back online, then unseal the new Vault containers. Complications arose in bringing Consul back into a healthy state as one of the pods was stuck in the “Terminating” state, which caused the discovery mechanisms for Consul servers to get stuck expecting an additional server to participate in elections. Once this pod was forcefully removed and allowed to be re-created, recovery commenced. These backing services being offline cause new containers launched to serve PyPI’s applications to fail. As a result, containers rescheduled due to node replacements were unable to start. This eventually caused PyPI to become unresponsive at 18:46 UTC as more and more containers were rescheduled by Kubernetes in an attempt to meet the specified instance count.
PyPI experienced an outage in its backends from 18:46-18:53 UTC on 2022-07-28. This outage stemmed from a cascading failure in the backend infrastructure that disrupted the management layer that deploys and secures PyPI's application servers. It is now resolved.
Report: "Queue delay affecting CDN purges and emails"
Last update### Summary PyPI initially experienced delays in features which used a centralized task queue \(such as purging the CDN cache and sending emails\) due to a poorly performing task type. This was followed by an outage due to the combination of the steps taken to mitigate the queue issue and unrelated changes that affected PyPI’s performance, resulting in PyPI becoming unavailable via the web or for installations. ### Details On Thu, 23 Jun 2022 at 04:55 UTC, PyPI admins deployed a change which introduced a new periodic task designed to aggregate statistics about 2FA usage on PyPI. This task was designed to run every 5 minutes and sampled multiple counts of different characteristics of 2FA usage. This task used a database query that attempted to count a large number of rows, and had poor performance, causing high database utilization and a long processing time for the task. However, while long-running, the task was finishing and publishing metrics, and so PyPI admins were unaware of its poor performance. Over time, however, the tasks that workers were actively working on began to include more and more of these poorly-performing tasks, exhausting the number of available workers to process other tasks. On Sun, 26 Jun 2022 at 17:29 UTC, PyPI admins deployed an unrelated change which replaced the JSON serializer used by PyPI from the standard library JSON serializer to a third-party JSON serializer, with benchmarks indicating that this would result in a 6x savings on time to serialize JSON, and thus a significant savings on response time for PyPI’s various JSON-rendering endpoints. At 21:06 UTC, PyPI admins began to receive reports that newly published versions were not being immediately updated in the web frontend for PyPI, not installable, and that emails were delayed. However, because the queue backlog was sufficiently small at this point, this small number of early reports were resolved within an hour and attributed to transient errors. Over the course of the following 12 hours, which coincided with the US EST evening, night and early morning, PyPI admins received an increasing stream of user reports that emails were delayed and project pages were not updating. On Mon, 27 Jun 2022 at 15:43 UTC, PyPI admins determined that PyPI’s task queue had a significant backlog, with more than 46K pending tasks, with the oldest task being more than 14 hours old, and began attempting to mitigate the backlog. PyPI admins determined that the backlog correlated with an increase in CPU usage by the database, and that there were at least two poorly-performing queries: one which had been introduced in the task for the 2FA metrics, and another which was due to a historical implementation detail of how PyPI projects are modeled in the database, where normalized project names are not stored in the database, but generated upon request based on the un-normalized project name To mitigate the load on the database, PyPI admins immediately began canceling the long-running database queries that resulted from the poorly performing task, in an attempt to remove as many as possible from the queue and free up workers to complete other tasks. Simultaneously, admins prepared two separate changes to mitigate the two poorly-performing queries: one to temporarily disable the poorly performing metrics task, and a second to add a column in the database which stored the normalized project name. At 15:53 UTC, PyPI admins deployed the first change that disabled the 2FA metrics task, which resulted in stopping additional long-running queries from being created. Admins continued to manually reap the poorly performing query as PyPI’s workers began to drain the backlog of other tasks. At this time, the size of the queue began to decrease. At 16:19 UTC, PyPI admins deployed the second change which added a column for the normalized project name. This included a large migration which unexpectedly locked PyPI’s database for a significant amount of time, resulting in PyPI backends being unable to create new database connections, becoming unhealthy, and causing responses to fail. At 16:45 UTC, the migration finished and PyPI backends began to recover, however PyPI still continued to intermittently return errors and did not become fully healthy, which was not explicable based on the previous mitigations. After investigation, PyPI admins determined that workers were crashing due to exceeding their allotted memory usage. Admins determined that the natural increase in requests after having an outage resulted in a large amount of memory being consumed by the new JSON serializer, which had higher memory footprint than the previous JSON serializer. At 17:41 UTC, PyPI admins deployed a change reverting the new JSON serializer back to the original serializer, and backends eventually returned to healthy status. ### Impact As a result of the task queue becoming increasingly large, user-facing tasks such as CDN purges and emails became more and more delayed. Delayed CDN purges meant that the PEP-503 ‘simple’ API was not getting updated and installers were unable to become aware of newly-published packages or new versions of existing packages. Additionally, the web frontend was not displaying new versions or new packages. Users attempting to create accounts and verify email addresses were unable to do so as well. At the peak, the task queue had nearly 50K pending tasks, and the oldest task in the queue was more than 14 hours old, whereas this queue normally has less than 100 pending tasks on average and tasks are completed in less than 1 second. 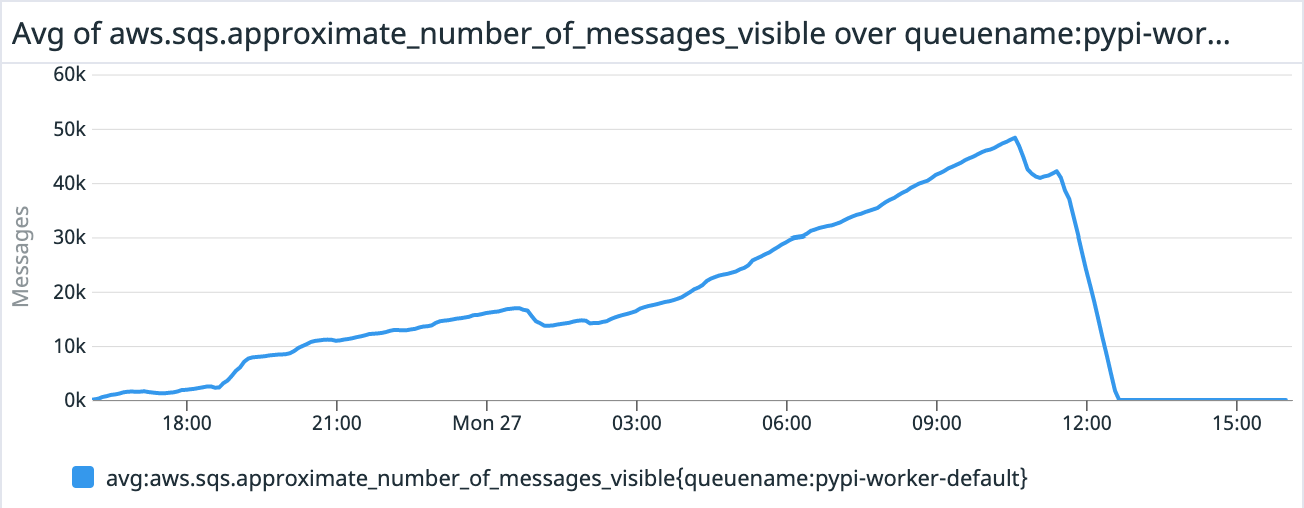 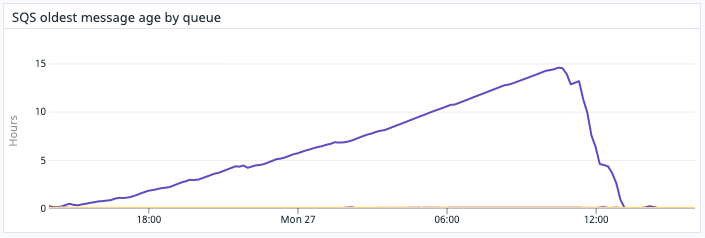 As a result of the locked migration, PyPI backends became unhealthy and served 500-level errors to users, preventing much of the web traffic, API traffic and uploads from succeeding for approximately 40 minutes. 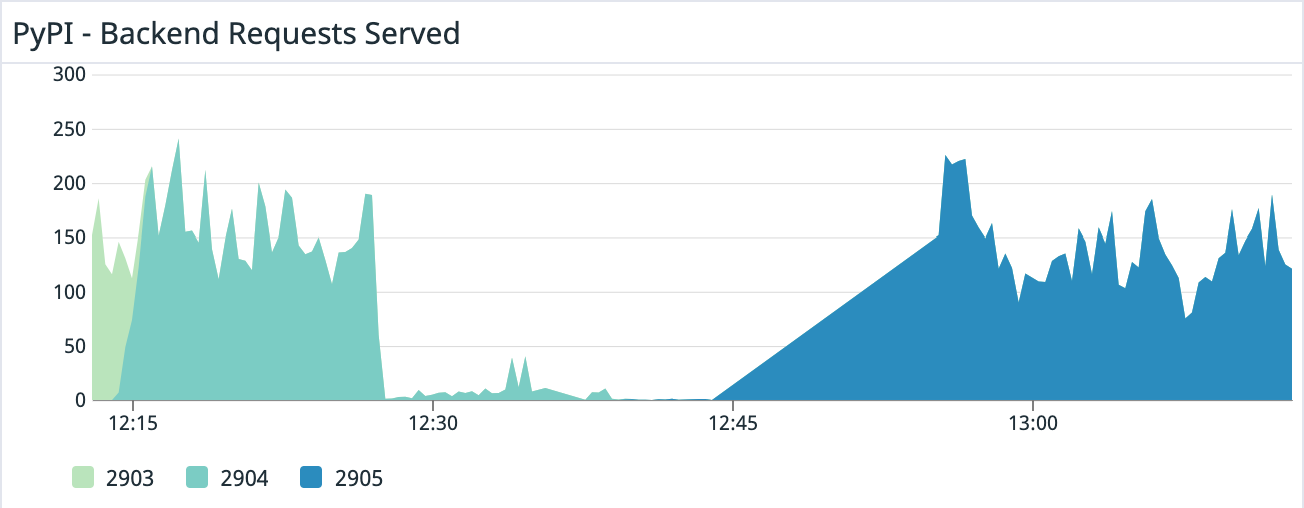 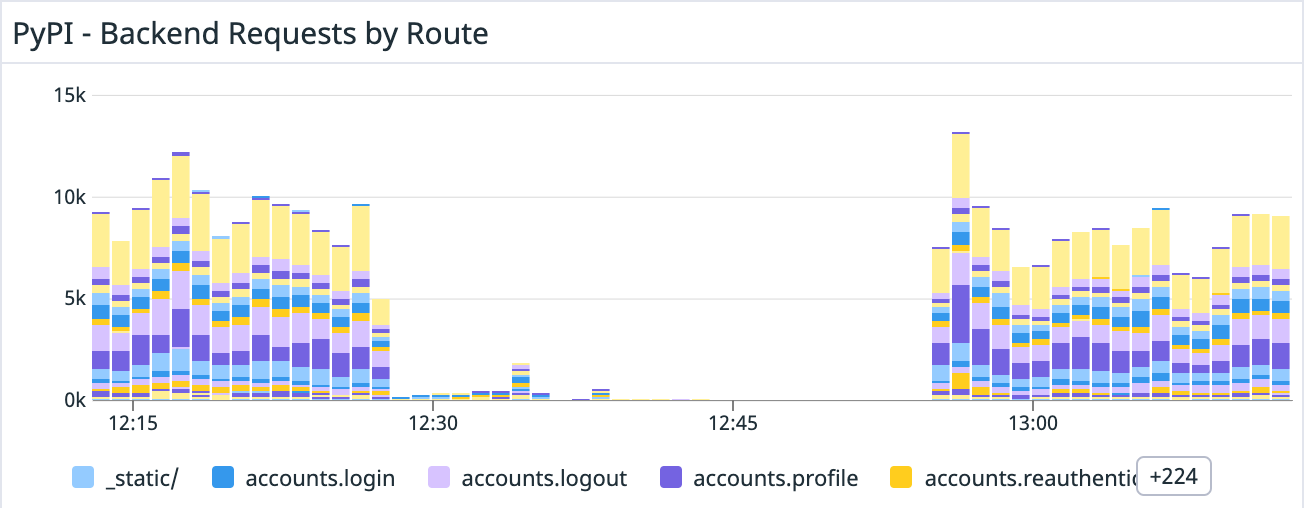 As a result of the increased memory usage due to the new JSON serializer, the PyPI backends did not fully recover from the prior outage and continued to return intermittent errors as pods consumed their available memory and were terminated. During the entire process, PyPI deployments were delayed due to their dependence on a successful run of a shared CI pipeline which had a significant backlog at the time changes were attempting to be introduced. This impacted the delivery times for changes to mitigate the issues. ### Future work During the outage, it was identified that the service PyPI uses for alerting and monitoring was insufficiently configured to notify the team of an excessively large task queue, which would have given administrators early warning that the 2FA metrics task was failing to complete and that delays were increasing. Additionally, the monitoring system lacked alerts for high CPU utilization in the database which was indicative of poorly performing queries. Alerts for both of these have already been added. When PyPI admins re-enable the 2FA metrics task, it will be redesigned to speed up queries by denormalizing counts rather than naively counting rows. In order to mitigate delays in PyPI’s CI pipeline, PyPI admins will migrate PyPI’s source repository to a separate organization, in order to ensure that the CI queue remains small and changes can be quickly deployed. In order to prevent long-running migrations from locking the database for extended periods of time, PyPI’s migration runner will be modified to make migrations safer, including adding timeouts after a certain short period of time rather than block for an arbitrarily long time. In order to mitigate complications when attempting to recover from an outage, PyPI admins will implement a policy to ensure that changes which are not directly related to the recovery efforts will not be merged until the outage has been resolved.
This incident has been resolved.
Backends are recovering
A long running migration has caused our backends to become unhealthy, affecting all web traffic.
We've disabled the specific tasks causing delays in the queue and are continuing to monitor the queue as it drains.
We've identified specific jobs in our queue that are causing processing delays and are working to remove them.
We are continuing to investigate this issue.
A delay in our job queue is affecting CDN purges causing public pages to be stale and delays in email sending for notifications, email validation, password resets, etc.
Report: "PyPI Backends unavailable."
Last updateThis incident has been resolved.
A fix has been implemented and we are monitoring the results.
We are currently investigating this issue.
Report: "Redirect Loops on JSON API endpoints."
Last update## Summary PyPI's JSON API experienced an incident that caused redirect loops to occur for all clients when requesting many of the endpoints available on the service. These endpoints provide JSON documents describing projects and specific releases of projects hosted on [pypi.org](http://pypi.org). This incident was initiated by changes intended to make the JSON API more performant and less of a burden on the PyPI backends. Specifically, the combination of [this change to the warehouse codebase](https://github.com/pypa/warehouse/pull/11546) and [this change to the CDN configuration for PyPI](https://github.com/python/pypi-infra/pull/87) update the canonical locaiton for accessing the JSON documents deterministic. This allows for deeper cache efficiency and the ability to move redirects to the canonical URL out to the CDN edge. The result is faster response times for clients and reduced load on the PyPI backends. The redirect updates specifically had an unintended consequence that led to this outage. Namely the existing elements in cache for the "normalized" project names redirected to the verbatim names of projects. Example: * Before * `/pypi/pyOpenSSL/json` "verbatim" project name url returns a `200` with the document and is canonical. * `/pypi/pyopenssl/json` "normalized" project name url `301` redirects to canonical URL. * After * `/pypi/pyOpenSSL/json` "verbatim" project name url returns a `301` redirect to canonical URL. * `/pypi/pyopenssl/json` "normalized" project name url returns a `200` with the document and is canonical. The issue at hand is that what is intended to the new canonical URL using the "normalized" project name was cached for _many_ projects, and that cache included a redirect to the "verbatim" project name, which... redirected back. ## Impact This impacted any client of the PyPI JSON API. These include the `poetry` tool for installing and managing Python dependencies, mirroring tools such as `bandersnatch`, and even our own internal service that redirects legacy file URLs on [files.pythonhosted.org](http://files.pythonhosted.org) to their new locations. The outage began with the deployment of [this change to the warehouse codebase](https://github.com/pypa/warehouse/pull/11546) and [this change to the CDN configuration for PyPI](https://github.com/python/pypi-infra/pull/87) at approximately 2022-06-10T10:50 UTC and continued to impact some URLs in a "long-tail" fashion through to 2022-06-10T16:00 UTC. Most notably project names beginning with `p` were the last to be affected as it is the most common first letter for projects uploaded to PyPI. ## Mitigation The changes described that led to this outage have been actively being attempted for over 6 weeks after more than a year of being aware of the problem. When faced with a system that was functioning correctly, but required purging of cache to be fully established the PyPI administrator managing the deployment chose to roll forward rather than roll back, knowingly extending the impact of this incident in favor of getting PyPI to a more maintainable state for serving the JSON API into the future. Because of the massive scale of PyPI's caches it was untenable to specifically purge bad URLs, leading to a need to clear the entire PyPI cache. This was undertaken by kicking off pools of processes that would iterate over individual first letters of project names to purge the entire project cache in parallel over a 1-2 hour duration. This duration was required as purging the entire cache would have overloaded the backends for PyPI in such a way that even with massive temporary scale up/out the load would have been too much for our backend and led to _many more hours_ of outage across the entire service. While most of the purges completed within the two hour estimate, the letter `p` was the final sgement, taking nearly 4 hours due to the popularity of the `py` prefix on the index. While the purges were ongoing PyPI's backends even in a scaled out state provided lackluster response times and performance as the caches were slowly refilled. ## Future work Issues have been filed to create better tooling to safely and expediently purge the caches and to limit the blast radius of purges in the future. We will also begin to research ways to build more confidence and expose these kinds of errors in our review process for changes to the configuration of our CDN.
This incident has been resolved.
All purges of JSON API documents have completed. Our backends are recovering from the added load of repopulating the entire cache. Any failed purges may result in latent redirect loops for specific projects or releases in the JSON API, these will self-resolve within 24 hours as caches expire.
The cache purge has cleared all but projects starting with the letter `p`. Our estimates failed to take into consideration the popularity of project names on PyPI starting with p 🙃
Our mass purge operation is continuing. Based on the current rate that we're able to process all purges the processes should be complete in 45-60 minutes.
We have started a task which will iterate over all projects and purge the cache for each individually. This will keep the PyPI backends from being overloaded by a completely bare cache. This process will take some time to complete, current estimate is 1-2 hours.
Some cached responses are causing redirect loops for endpoints on the JSON API. We are working to determine how to clear these cached values without impacting the overall health of PyPI.
Report: "Newly uploaded files are returning 403 from files.pythonhosted.org"
Last update## Summary The cloud infrastructure that runs PyPI is managed via an automation tool which allows for configuration changes to be version controlled, reviewed, and deployed automatically. This tool includes multiple backends for state sharing and locking to facilitate collaboration between multiple contributors. While migrating the remote state backend and locking features to a more robust hosted platform an error was made when setting the credentials that grant our CDN access to the object storage where uploaded files to PyPI are hosted. The result was that newly uploaded files as well as files that had expired from our CDNs cache were unavailable. The outage began 2022-06-022 20:28 UTC and was initially mitigated 2022-06-02 22:38 UTC by rolling back the configuration to a previous version. The configuration issue in the hosted platform was confirmed and corrected 2022-06-02 12:00 UTC and a corrected new version of the CDN configuration was deployed. Future deploys will include this value and will not regress in the same manner. ## Details As the Infrastructure team at the PSF onboards a new hire and the clunkiness of collaborating on our terraform configuration led to only two people having the ability to deploy changes, a decision was made to migrate all state, sensitive variables, and locking to a hosted backend for terraform. This will allow all those with appropriate access \(PyPI Admins and PSF Infrastructure Staff\) access without having to pass around plaintext secrets necessary to plan and apply changes to the infrastructure. During the migration from S3 state storage and DynamoDB locking to Hashicorp Terraform Cloud, the Infrastructure staff lead made an error in copying the value for the GCS secret access key that grants Fastly, our CDN, access to read the Cloud Storage bucket where PyPI uploads are stored. Because the value was marked as sensitive in Terraform Cloud via a setting, it wasn’t obvious to the staff member when planning the changes what would change, and it was assumed to be an artifact of that setting. As a confirmation and for assurances, the staff member configured the changes to Fastly configuration to _not_ auto activate the new configuration. After applying the changes which would not be automatically activated in Fastly it is unclear why the incorrect change was not identified when diffing service configurations, but ultimately it was missed and the services were activated. Impact lasted 130 minutes until enough signal from users was raised to alert PyPI admins and affected all new uploaded files as well as any files that had expired from our CDN caches. ## Future Mitigation This outage highlighted two key areas where improvements can be made to ensure timely response 1. **More thorough automated monitoring of file access via our CDN.** Due to the caching nature of our CDN, it was not detected that this error was occurring as the file checked never expired from cache. We will implement a monitor that checks for a file that is explicitly not cached to ensure that the entire system from client to object-store is working appropriately 2. **Improvements to secrets handling in our infrastructure automation.** We carried some legacy practices for storing secrets/configuration in our systems that led to pertinent configuration value being obscured in a complex object rather than an individual key. We’ll refactor this to make detecting changes to values more obvious to contributors to the project.
We have resolved this incident, identified the cause of the breakage, and completed ensuring that it will not regress. An incident report will be provided shortly.
A fix has been implemented and we are monitoring the results.
The issue has been identified and a fix is being implemented.
We are currently investigating this issue.
Report: "Malicious takeover of ctx project on PyPI."
Last updateTakeover of the ctx project was reported on multiple channels overnight and was mitigated as of 6:07 AM Eastern. We confirmed via investigation that this compromise was of a single user account due to re-registration over an expired domain. The domain that hosted the users email address was re-registered 2022-05-14T18:40:05Z and a password reset completed successfully for the user at 2022-05-14T18:52:40Z. Original releases were then deleted and malicious copies uploaded. PyPI itself was not directly compromised. Read the full incident report at [https://python-security.readthedocs.io/pypi-vuln/index-2022-05-24-ctx-domain-takeover.html](https://python-security.readthedocs.io/pypi-vuln/index-2022-05-24-ctx-domain-takeover.html).
This incident has been resolved.
Report: "Redirect and ancillary services unavailable."
Last updateThis incident has been resolved.
Our IP with the hosting provider was temporarily restricted due to a DDoS event, and is back online.
A networking issue with our hosting provider is currently impacting various redirects and ancillary services operated by a load balancer. We have opened a ticket and are awaiting response.
Report: "PyPI Down"
Last updateAt approximately 15:00 UTC, the TLS certificates that PyPI’s internal deployment tooling uses to secure access to Vault expired. This led to a cascading failure within the PyPI infrastructure that caused running pods to lose access to secure credentials and stopped new instances from being launched. Under normal circumstances, this would have been resolved as the Vault instances restarted and retrieved a new TLS certificate, but an abnormally large backlog of expired leases caused the new Vault instances to crash on startup and required manual intervention to cleanup extraneous leases. The initial remedy will be to upgrade our Vault instances to a version that resolves the crash on launch issue when the quantity of expired leases is too high, which would allow for this outage to have been recovered in a more automated fashion. Longer term, research and development time will be allocated to improving the automation around detection of instances nearing expiration as well as mechanisms to securely automate the unseal process for our secure storage.
This incident is resolved.
Applications are coming back online and we are monitoring for stability.
Core failed service has been identified and is coming back online. Next we'll bring up the ancillary services. Once all our automation services are online we can begin to bring the applications back.
All backend services for PyPI are down due to a cascading failure in our deployment tooling. We are investigating and working on restoring service.
Report: "PyPI Backends unavailable."
Last updateThis incident has been resolved.
A number of our backend services entered a crash loop, that the reaper in place to restore those pods could not keep up with. As crashed pods were reaped our capacity came back online. We are monitoring to ensure stability.
We are currently investigating this issue.
Report: "python.org backends unavailable."
Last updateThis incident has been resolved.
Backend provider appears to have experienced an outage. Services are back online and we are monitoring for confirmed resolution.
We are currently investigating this issue.
Report: "PyPI XMLRPC Search Disabled"
Last updateXMLRPC Search has been permanently disabled.
We are now at 100 days since the decision to disable the XMLRPC search endpoint. Traffic to the endpoint has not subsided in any substantial way and we have not heard from any of the parties who continue to issue hundreds of thousands of search calls per hour. As such, XMLRPC search will be permanently disabled.
The XMLRPC Search endpoint remains disabled due to ongoing request volume. As of this update, there has been no reduction in inbound traffic to the endpoint from abusive IPs and we are unable to re-enable the endpoint, as it would immediately cause PyPI service to degrade again.
We are continuing to monitor for any further issues.
The XMLRPC Search endpoint remains disabled due to ongoing request volume. As of this update, there has been no reduction in inbound traffic to the endpoint from abusive IPs and we are unable to re-enable the endpoint, as it would immediately cause PyPI service to degrade again.
The XMLRPC Search endpoint is still disabled due to ongoing request volume. As of this update, there has been no reduction in inbound traffic to the endpoint from abusive IPs and we are unable to re-enable the endpoint, as it would immediately cause PyPI service to degrade again. We are working with the abuse contact at the owner of the IPs and trying to make contact with the maintainers of whatever tool is flooding us via other channels.
The XMLRPC Search endpoint is still disabled due to ongoing request volume. As of this update, there has been no reduction in inbound traffic to the endpoint from abusive IPs and we are unable to re-enable the endpoint, as it would immediately cause PyPI service to degrade again. We are working with the abuse contact at the owner of the IPs and trying to make contact with the maintainers of whatever tool is flooding us via other channels.
With the temporary disabling of XMLRPC we are hoping that the mass consumer that is causing us trouble will make contact. Due to the huge swath of IPs we were unable to make a more targeted block without risking more severe disruption, and were not able to receive a response from their abuse contact or direct outreach in an actionable time frame.
Due to the overwhelming surges of inbound XMLRPC search requests (and growing) we will be temporarily disabling the XMLRPC search endpoint until further notice.
We've identified that the issue is with excess volume to our XLMRPC search endpoint that powers `pip search` among other tools. We are working to try to identify patterns and prohibit abusive clients to retain service health.
PyPI's search backends are experiencing an outage causing the backends to timeout and fail, leading to degradation of service for the web app. Uploads and installs are currently unaffected but logged in actions and search via the web app and API access via XMLRPC are currently experiencing partial outages.
Report: "Outage"
Last updateThis incident has been resolved.
We identified and resolved an issue in our database causing the CPUs to be exhausted. An index which should have been utilized for a common query was being bypassed by the planner. After forcing a statistics run of the table in question the query performance returned to expected performance. We are monitoring the status of the database now and are researching methods of avoiding this in the future.
PyPI is currently experiencing an outage, and we are investigating.
Report: "Service Interruption due to database upgrades"
Last updateThis incident has been resolved.
Database maintenance is now complete and services are back online. We are monitoring the stability of backend services.
Upload functionality is now restored. We are monitoring our database load before bringing the UI back online.
Database upgrade is completing and we are working to bring the backends back online soon.
PyPI is currently experiencing interruptions due to a major database upgrade that cannot be performed online. We did not recognize this would occur when initiating the upgrade. Service will be operational once the upgrade completes.
Report: "PyPI Download Statistics Not Updating"
Last updateThis incident has been resolved.
We have backfilled all data to the `bigquery-public-data:pypi.simple_requests` and `bigquery-public-data:pypi.file_downloads` tables, and are monitoring our newly rearchitected pipeline to ensure that our new strategy will perform as expected moving forward. Please note that the `the-psf` dataset has not, and may not be backfilled or updated after 2021-11-22. If you are currently using `the-psf:pypi.file_downloads` or `the-psf:pypi.simple_requests` tables, you should migrate to the `bigquery-public-data` dataset to query the latest data.
We have begun the process of rearchitecting our data processing pipeline to get below the quotas that are impacting and should begin loading the backlog of data and processing new incoming over the next few days.
We've identified an issue with the PyPI download statistics documented at https://packaging.python.org/guides/analyzing-pypi-package-downloads/ not updating. A resource quota with our backend providers has been exceeded and we are looking into how to resolve the issue. It may be some time before this can be addressed, but statistics in the meantime should be recoverable.